
Building a Singapore Food Classifier — Part 3: Case Studies — What the Model Gets Right, Wrong, and Why
Part 3 of building Hawker AI — walking through real predictions to understand what the model has actually learned, and where it breaks down.
Part 1 covers data collection and training. Part 2 covers deployment and architecture.
Why case studies matter
An overall accuracy number — 79.3% — tells you almost nothing about whether a model is useful. What matters is: when does it succeed? When does it fail? And can you predict which one you’ll get?
I went through the test set and pulled out representative cases from each category: confident correct predictions, confident wrong predictions, and the messy middle ground where the model is uncertain. Each one tells a story about what the model has learned — and what it hasn’t.
The confident wins
Here’s what a strong prediction looks like in the live app — chicken rice identified at 92% confidence, labelled “IDENTIFIED” in green, with nutrition data and alternative predictions:
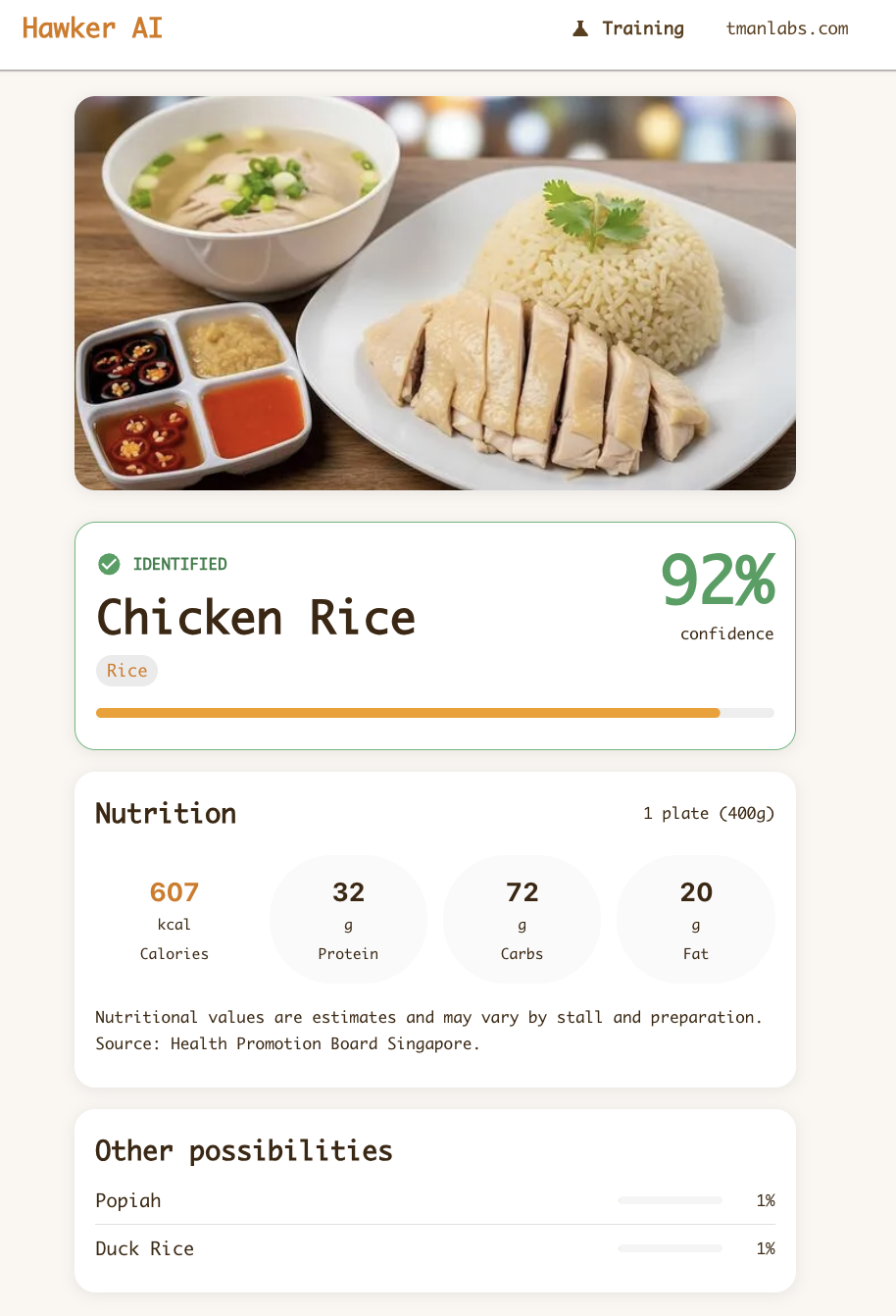
These are cases where the model predicts correctly with high confidence (>85%). They share a pattern: the dish has a distinctive visual signature that’s hard to confuse with anything else.
Chilli Crab — 100% accuracy
Why it works: Chilli crab is a whole crab in bright red-orange sauce, usually served on a large plate. No other dish in the dataset looks remotely similar. The model has strong, unambiguous features to latch onto: the crab shell shape, the vivid red colour, the sauce pooling on the plate.
What it tells us: When a dish has unique geometry (not just “stuff in a bowl”), the model performs extremely well. The crab’s shape is a stronger signal than any colour or texture feature.
Kaya Toast — 100% accuracy
Why it works: Kaya toast has a very specific visual pattern — rectangular toast slices, often with soft-boiled eggs on the side, served on a flat plate or tray. The brown-and-white colour scheme (toast + eggs) and the geometric shape of the bread are distinctive.
What it tells us: Strong geometric features (rectangles, distinct component arrangement) give the model reliable signals. The toast-and-eggs combination doesn’t appear in any other class.
Bak Kut Teh — 100% accuracy
Why it works: Pork rib soup in a clay pot. The combination of a distinctive clay pot, visible pork ribs, clear/dark broth, and the typical side condiments creates a unique visual signature.
What it tells us: Container shape matters. A clay pot is a strong distinguishing feature because almost no other hawker dish is served in one.
Satay — 90% accuracy
Why it works: Skewered meat on sticks, usually with a peanut sauce dip. The skewer shape is a powerful geometric signal — long parallel lines — that no other dish has.
What it tells us: Repeated geometric patterns (parallel skewer sticks) are very learnable. Even when the grilling style or meat colour varies, the skewer shape is consistent.
Curry Puff — 95% accuracy
Why it works: A golden-brown pastry with a distinctive crimped edge shape. The triangular/half-moon form and the fried surface texture are unique in the dataset.
What it tells us: The model can learn shape outlines well. A curry puff’s silhouette is different from every other dish.
The pattern
Dishes that score 90%+ share one or more of these:
- Unique shape — crab, toast rectangles, skewers, pastry crimps
- Distinctive container — clay pot, skewer rack
- Strong colour contrast — chilli crab’s red, kaya toast’s brown-on-white
- No visual overlap with other classes
The confident failures
These are cases where the model predicts with reasonable confidence — but gets it wrong. These are more instructive than the successes because they reveal what features the model is actually using (and misusing).
Bak Chor Mee → predicted as Mee Pok (5 test images)
What happened: The model saw dry noodles with minced meat in a bowl and called it mee pok. The correct answer was bak chor mee.
Why it fails: These two dishes are nearly identical. Both are:
- Dry (no soup) noodles in a bowl
- Topped with minced pork
- Served with vinegar and chilli
- Photographed from above showing the same circular bowl shape
The actual difference is the noodle type — bak chor mee traditionally uses thin mee kia noodles, while mee pok uses flat, wide noodles. But when photographed from above at typical phone-camera distance, the noodle width difference is barely visible.
What it tells us: The model can’t reliably distinguish fine-grained texture differences (thin vs flat noodles) at typical photo resolution. It’s learned “dry noodles + minced meat + bowl = one of these two” but can’t go further.
Mee Pok → predicted as Bak Chor Mee (5 test images)
What happened: The exact reverse — same confusion, same reason. This bidirectional confusion (5 errors in each direction) confirms it’s a systematic similarity problem, not random noise.
What it tells us: When the confusion is symmetric and consistent, the classes are genuinely ambiguous. More training data won’t fix this — the visual features simply overlap too much.
Hokkien Mee → predicted as Char Kway Teow (2 test images)
What happened: The model saw stir-fried noodles and called it char kway teow instead of hokkien mee.
Why it fails: Both dishes are wok-fried noodles with dark soy sauce. The visual similarities:
- Dark-coloured noodles from soy sauce
- Visible wok hei (charred marks)
- Similar garnishes (bean sprouts, chives)
- Served on a plate, not in a bowl
The actual difference: hokkien mee has a wet/gravy consistency and uses thick yellow noodles mixed with thin rice noodles. Char kway teow uses flat rice noodles and is drier. But under hawker-centre lighting in a phone photo, these distinctions blur.
What it tells us: The model has learned “dark wok-fried noodles” as a feature cluster but can’t distinguish subtypes within it. It would need close-up texture information that most photos don’t provide.
Prawn Noodles → predicted as Hokkien Mee (3 test images)
What happened: Both dishes feature prawns with noodles prominently. The model saw prawns + noodles and went with hokkien mee.
Why it fails: Prawns are a strong visual feature — bright orange/pink, distinctive curved shape. Both dishes have them. The distinguishing feature should be that prawn noodles is a soup (broth visible) while hokkien mee is fried (no broth). But some photos show the dish at an angle where the broth level isn’t visible.
What it tells us: The model is correctly detecting prawns — that’s good. But it weights “prawn presence” too heavily because both training classes have prominent prawns. A human would look at the broth vs no-broth distinction, but the model hasn’t learned that as a discriminating feature.
Chicken Rice → predicted as Economy Rice (3 test images)
What happened: The model saw rice with meat and called it economy rice instead of chicken rice.
Why it fails: A plate of chicken rice — rice, sliced chicken, cucumber, sauce — can look surprisingly similar to a plate of economy rice with chicken as the selected protein. The key visual difference is the arrangement: chicken rice has consistently sliced chicken laid over rice, while economy rice has a mix-and-match look. But not every chicken rice photo follows the classic presentation.
What it tells us: The model struggles when the “classic” presentation varies. A perfectly arranged chicken rice plate is easy to classify. A messy one, or one shot from an unusual angle, looks like any other rice plate.
The messy middle: low-confidence predictions
These are cases where the model’s top prediction is below 60% confidence — it’s uncertain, and for good reason.
Economy Rice — 35% accuracy overall
Economy rice is the model’s worst class, and it’s the most interesting failure case.
The fundamental problem: Economy rice has no consistent visual identity. It’s defined by the ordering process (point at dishes behind glass), not by the dish itself. Two plates of economy rice can look completely different depending on what the customer chose.
Some examples from the test set:
- Plate with fried chicken, vegetables, and egg → model predicts chicken rice (wrong, but understandable)
- Plate with fish, tofu, and greens → model predicts nasi lemak (wrong)
- Plate with curry, rice, and sambal → model predicts nasi goreng (wrong)
Each of these predictions is “correct” in the sense that the plate’s contents genuinely resemble the predicted dish. The model is identifying the food correctly — it just doesn’t know the meta-concept of “this is economy rice because of how it was ordered, not how it looks.”
What it tells us: Some classification tasks are inherently visual (what shape is this food?) and some are contextual (how was this food ordered?). A pure image classifier can only do the first kind. Economy rice is a contextual category that no amount of visual training can reliably capture.
Laksa — 65% accuracy
Laksa should be distinctive — it’s a soup with thick curry-coloured broth, coconut milk, and noodles. When photographed clearly with the red-orange broth visible, the model nails it.
But laksa fails when:
- The photo is taken from directly above and the broth isn’t visible (looks like any noodle dish)
- The variant is assam laksa (clearer, less red broth) which looks different from curry laksa
- The garnishes (bean sprouts, herbs) dominate the frame and the broth colour is hidden
What it tells us: Broth colour is a critical feature for soup dishes. When it’s visible, the model uses it effectively. When it’s not — due to camera angle, lighting, or garnish coverage — the model loses its best signal.
Carrot Cake — 70% accuracy
“Carrot cake” in Singapore is chai tow kway — fried cubes of radish cake with egg. It looks nothing like a Western carrot cake. But DuckDuckGo doesn’t know that.
Even after cleaning, some borderline images remained — radish cake that’s heavily browned looks like fried tofu, fried potatoes, or even hash browns. The model confuses it with:
- Oyster omelette (both are egg-fried dishes)
- Char kway teow (both have dark soy sauce)
- Murtabak (both are flat, fried, brown)
What it tells us: Dishes defined by a cooking method (pan-fried with egg and soy sauce) rather than a unique ingredient share visual features with every other dish cooked the same way.
Patterns across all cases
Looking at all the successes and failures together, a few clear patterns emerge:
What the model has learned well
- Shape and geometry — crab shells, toast rectangles, skewer sticks, curry puff crimps. Strong shape = high accuracy.
- Container type — clay pot (bak kut teh), dessert bowl (chendol, ice kachang), flat plate vs deep bowl. The container is often more informative than the food itself.
- Distinctive colours — chilli crab red, chendol green, ice kachang rainbow. Unique colour = reliable classification.
- Component count and arrangement — kaya toast’s toast-plus-eggs layout, satay’s multiple skewers. Consistent spatial patterns are learnable.
What the model struggles with
- Fine-grained texture differences — thin vs flat noodles, minced vs sliced meat. The pixel-level detail needed isn’t available in typical phone photos.
- Contextual categories — economy rice is defined by how it’s ordered, not how it looks. The model can’t learn non-visual concepts.
- Cooking method overlap — many dishes share the same cooking method (wok-fried with soy sauce, deep-fried) and therefore share visual features. The distinguishing information is often in the ingredient, which may not be visible.
- Angle dependency — some dishes are only identifiable from certain angles. Soup dishes need a side angle to show broth; top-down shots lose that information.
Would a human do better?
For most dishes, yes — because humans use context that the model doesn’t have access to:
- Container context — a human recognises a hawker tray, a clay pot, a banana leaf. The model sees shapes.
- Cultural knowledge — a human knows that “sliced chicken on rice with chilli sauce” is chicken rice. The model just sees pixels.
- Multi-sensory priors — a human can imagine the smell and texture from the photo. The model has no concept of these.
Some dishes are just hard.
Edge case: what happens when you upload something that isn’t food?
This is worth calling out because it’s a failure mode every image classifier has, and most demos don’t show it.
I uploaded an AI-generated abstract image — blue geometric shapes, no food in sight:
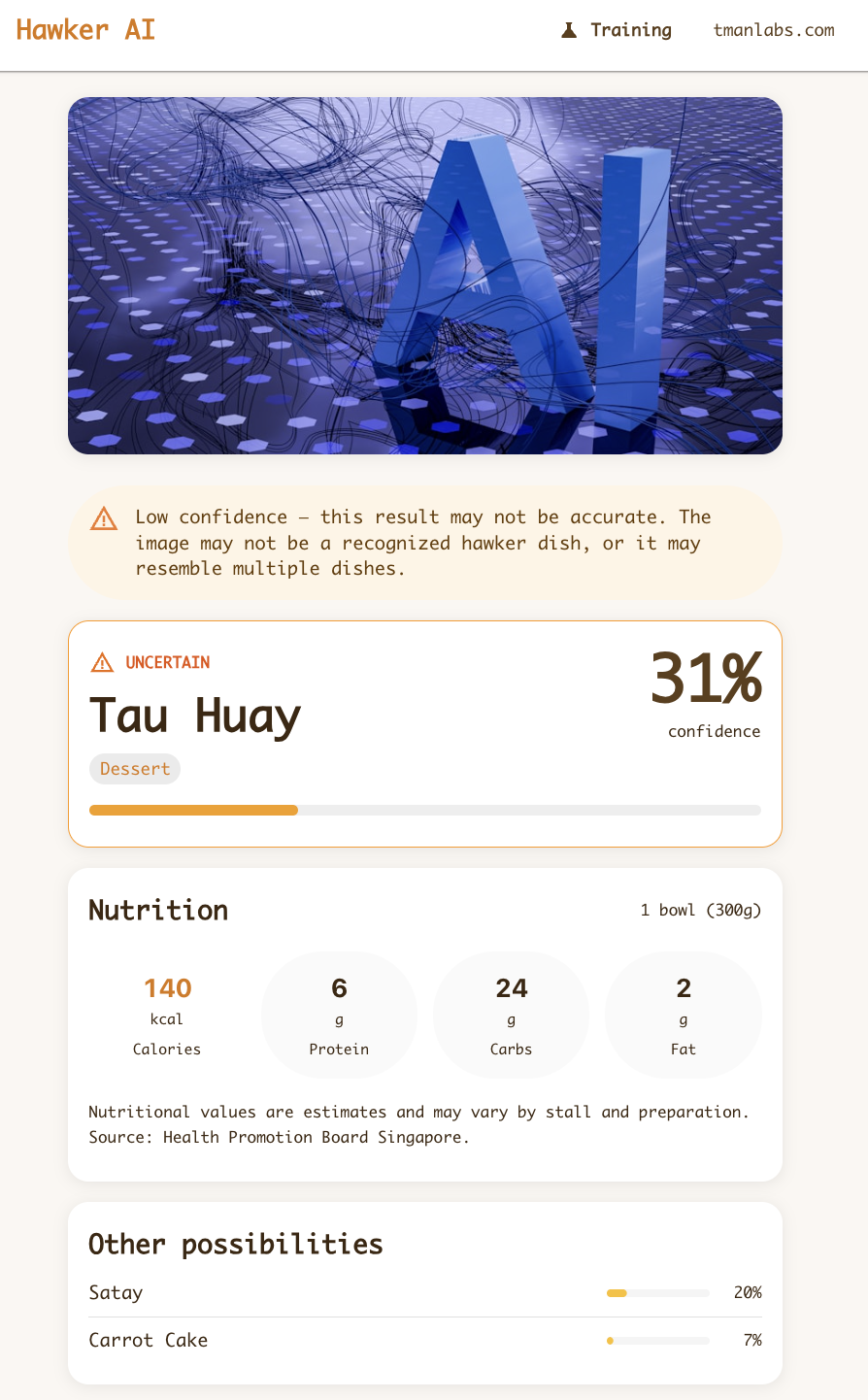
The model has no “this isn’t food” class. It’s trained on 30 hawker dishes and must pick one of them, no matter what you upload. A photo of a car, a screenshot of your desktop, a picture of your cat — the model will tell you it’s some kind of hawker food.
But the app now handles this with a confidence label system. High-confidence predictions are labelled “IDENTIFIED” in green. Low-confidence ones are labelled “UNCERTAIN” in orange, with a warning banner: “Low confidence — this result may not be accurate. The image may not be a recognized hawker dish, or it may resemble multiple dishes.”
31% across 30 classes is essentially random (uniform random would be ~3.3% per class), so the model correctly signals low confidence — and the UI now communicates that to the user instead of presenting it as a definitive answer.
What I’d change based on these cases
Add a confidence threshold— done. The app now labels predictions as “IDENTIFIED” or “UNCERTAIN” with a warning banner for low-confidence results.- Merge bak chor mee and mee pok into “minced meat noodles” — the visual distinction is below human reliability, so forcing the model to make it is unfair
- Remove economy rice as a class — it’s a contextual category that can’t be learned visually. Instead, classify the individual components (fried chicken, fried egg, vegetables)
- Add angle-aware augmentation — train with more top-down and side-angle crops so the model learns to handle both perspectives
- Weight the loss by class difficulty — give the model more gradient signal on hard classes and less on already-solved ones
- Ensemble with a text model — if the photo has visible signage or menu text, OCR could provide a strong secondary signal
But the most important lesson from these case studies isn’t about model architecture or training tricks. It’s this: the hardest part of image classification isn’t the model — it’s defining what a “class” means. When two dishes are visually identical, or when a category is defined by context rather than appearance, no amount of training will save you. The fix is in the problem definition, not the solution.
The app is live at hawker-ai.vercel.app.